- 正規表現 -

文字列がパターンと一致することを「マッチする」、一致しないことを「マッチしない」といい、マッチするかどうか調べる事をパターンマッチと言う。
◆メタ文字
| . |
任意の1文字 |
| |
選択 |
| * |
0回以上の繰り返し |
+ |
1回以上の繰り返し |
| ? |
0回または1回の繰り返し |
() |
正規表現のグループ |
| ^ |
先頭 |
$ |
末尾 |
| [] |
文字クラス |
{n} |
n回の繰り返し |
| {n,} |
n回以上の繰り返し |
{n,m} |
n回以上m回以下の繰り返し |
| \ |
メタ文字を文字として扱う |
|
|
◆文字クラスの使い方
| \w |
[0-9a-zA-Z_] |
半角英数とアンダーバー |
| \W |
[^0-9a-zA-Z_] |
半角英数と数字とアンダーバー以外 |
| \s |
[\t\n\r\f] |
空白(半角スペース、タブ、改行) |
| \S |
[^\t\n\r\f] |
空白(半角スペース、タブ、改行)以外すべて |
| \d |
[0-9] |
数字 |
| \D |
[^0-9] |
数字以外すべて |
文字列がパターンと一致することを「マッチする」、一致しないことを「マッチしない」といい、
マッチするかどうか調べる事をパターンマッチと言う。
$re1 = "I kike perl" =~ /perl/; # =~ マッチする
$re2 = "I kike perl" !~ /perl/; # !~ マッチしない
print $re1,"\n";
print $re2,"\n";
-------------------------
<<結果>>
1 #マッチした場合には1を返す。しない場合にはundef(空白)になる。
パターンは//で挟む。
$_ = "I kike perl"; #$_というスカラー変数に文字列が格納されている場合、
$b = /perl/; ←この書き方でもパターンマッチが出来る
print $b;
-------------------------
<<結果>>
1
$_ = "I kike perl"; #if文なんかで使う時便利!
$a = "perl";
if(/$a/){
print "マッチしています";
}
◆マッチした結果の取り出し方
| $& |
マッチした文字列全体を取得出来る |
| $` |
(アクサングラーブ)マッチした部分より前にある文字列 |
| $' |
マッチした部分より後ろにある文字列 |
| $1,$2,・・・・・ |
1番目、2番目・・・のグループにマッチした文字列 |
| $+ |
最後のグループにマッチした文字列 |
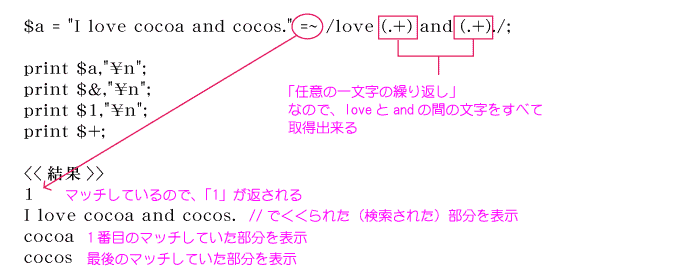
◆部分マッチ
$a = "cocoa" =~ /(c.)\1/; #一番最初にマッチした(c.)をaに格納する
◆マッチ演算子のオプション
| g |
/abc/g; |
マッチするものすべて見つける |
| i |
/abc/i; |
大文字と小文字を区別しない |
| m |
/abc/m; |
文字列を複数行として扱う |
| s |
/abc/s; |
文字列を単一行として扱う |
| x |
/abc/x; |
パターン内に含まれる半角スペースを無視する |
$a = "10,20,30";
@b = $a =~ /\d+/g; #\dは文字クラス→0-9までの数字。
gが付いているのですべて取得→配列bへ格納する。
print @b,"\n";
-------------------------
<<結果>>
102030

